Human-bot interaction in the formation of collective identities in Farsi twitter
For a collective action to take place, a collective identity, discursive community —or a collective voice, in a less strict sense— is formed through a dynamic process. Today, Online Social Networks (OSNs) have changed the way these collective identities or voices are shaped and the way actors come to constitute themselves as a collective or an online community. In shaping the collective identity in social media, the boundaries between inside and outside tend to get blurry, leading to a less concrete definition and more conflicts and negotiations in discursive space. We are interested to study these collective identities and the dynamic processes of their formations.
Although OSNs ephemeral role is clear in flash mobilization or the aggregation of the public around contentious issues, our focus is on the formation of a more steady phenomenon of collective identities (or discursive communities). Simple aggregation of individuals around a common cause does not create long-standing community and solidarity. We look at the individual actors on OSNs and ask whether collective identity is fostered through individual activities on OSNs. We also ask whether collective solidarity is shaped in different political, social, cultural, economic, and environmental issues or the process of using OSNs in general is more individualizing.
Among various OSNs, our focus is on Twitter. Twitter, as the most popular microblogging tool, has become a live source of discussion of current social and political events. Compared to other platforms, Twitter plays a significant role in facilitating the formation of online communities. It is more public and offers limited privacy by default, contributes more to the rapid spread of information, acts as the most timely platform in covering the news, and is the most commonly used corporate social media platform, (Min, Wilson, & Moon, 2014; Osborne & Dredze, 2014; Olteanu, Castillo, Diakopoulos, & Aberer, 2015).
We are, in particular, interested in the role of twitter bots in the process of the formation of these collective identities or discursive communities. Bot population is estimated to be between 5% to 15% of accounts on twitter, an estimation which excludes cyborgs and possibly very sophisticated bots that “escape a human annotator’s judgment” (Varol et. al., 2017). Twitter bots, frequently part of a botnet (or a group of coordinated bots), are used to perform simple and structurally repetitive tasks, with a much higher rate compared to that of humans. Bots tweet, retweet, mention, and follow other users/bots singularly or collectively in a coordinated manner (i.e. botnets). Automated programs or bots are developed to disrupt or influence online discourses, using spam hashtags and scam users, and exercise a profound impact on content popularity and activity on Twitter (Ferrara, Varol, Davis, Menczer & Flammini, 2016).
Dr. Kosar Karimipour Introduces the Farsi Twitter Project
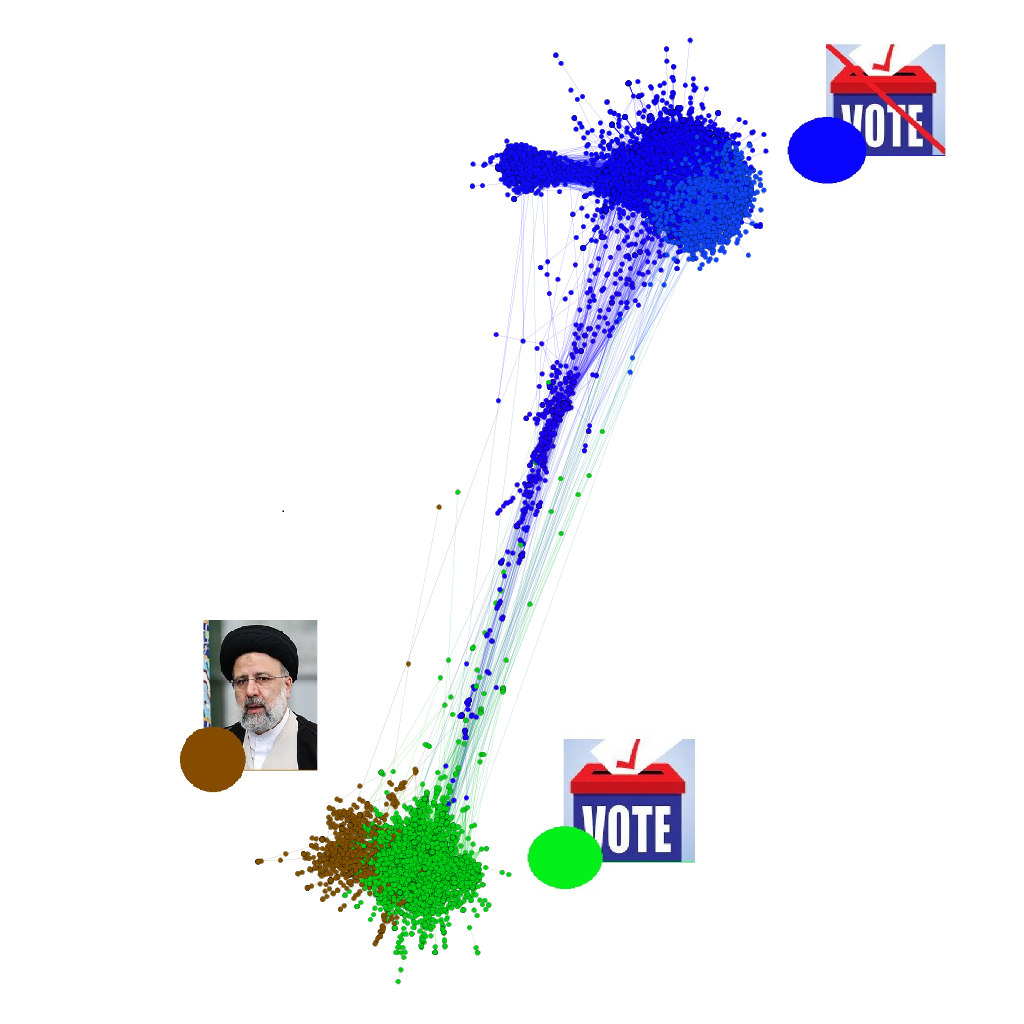
Among different types of bots, we focus on social bots, the type that aims to influence the public discourse on Twitter. Today, social bots and botnets attempt to play an opinion-making role in OSNs in general, and twitter in particular, by affecting or manipulating the discourse as a whole. A growing stream of research looks for, and quantifies, the effects of such coordinated activities on a range of topics from elections, to civil war and even advertisements (see for example Abokhodair, Yoo & McDonald, 2015; Bessi & Ferrara, 2016; Clark et. al, 2016). They are created by entities (individuals or organizations) with technical skills to the target population and promote content, with motivations to boost popularity or to influence public opinions (Bessi & Ferrara, 2016; Ferrara, et al., 2016). Frequently referred to as sybils, they seem to exert a disproportionately large influence on OSNs by creating pseudonymous identities. Researchers have studied the flow of information and ideas and social connectivity and showed how the behavior of bots is different in botnets (interacting with other bots) and outside of it (interacting with other humans) are interconnected (see for example Berger & Morgan, 2015; Bessi & Ferrara, 2016; Stella, Ferrara, & De Domenico, 2018). Following this stream of literature, we aim to detect the effect of social bots on online discourses on Farsi Twitter. Our research questions are focused on the interaction between human and bot users in the process of the formation of collective identities or discursive communities.
Bot-detection or classification of accounts into groups of bots, human users and possibly cyborgs in Farsi Twitter is the first step toward studying the patterns of communication among different classes of entities on the network. Easily detectable bots show lower levels of entropy, their tweet content follows spam patterns, and their account properties (e.g. URL ration, account name, tweeting device makeup) show more deviation from normal. Simple classification algorithms are built to detect these bots using metadata, such as the followers/followings ratio, tweeting frequency, account age, and the number of mentions/replies (Chu, Gianvecchio, Wang & Jajodia, 2012). However, over time, some bots have become more sophisticated in emulating the patterns of human activities and are now harder to detect. To detect more sophisticated bots a combination of features is usually evaluated. Features that are evaluated include twitter user metadata (e.g. default picture, length and the number of digits in the screen names and usernames, and per-hour and the total number of tweets, retweets, or followers, and timing (e.g. time between two (re)tweet)), follower/following network (e.g. language use, the distribution of account age, network density, and clustering coefficient), and content (e. number and entropy of words, the proportion of Part-Of-Speech tags, and sentiment analysis (e.g. number of emotions per tweet, and polarization score of each tweet) (Varol, e. al., 2017).
We use the Botometer API to get a bot-score for each account, and a classification mechanism to divide the account into bots, possible bots, and humans. Botometer is developed by Indiana University Network Science Institute (IUNI) and the Center for Complex Networks and Systems Research (CNetS) to classify an account as a bot or human (Yang et. al., 2019). After detecting the botnets (or users showing bot-like behavior) in Farsi twitter we seek to study the possible characteristic differences between botnets and human networks. We also ask what are the alternate discourses, narratives or hoaxes disseminated by botnets, and whether they are successful in disseminating them.
Once the required data from the Farsi Twitter is available, we aim to take a number of measurements and evaluate the corresponding metrics that could reveal informative patterns in the data. In particular, we need the continuous (gap-free) data for tweets in Farsi Twitter over a long-enough time interval, preferably including the follower-following metadata that could help us build the friendship network. In order to identify trends in the network, we necessarily need to study the data over time and it is essential that these time intervals span all stages of development of the Twitter conversations over issues corresponding to trending hashtags, from dawn to dusk of the trends. This enables us to run a meaningful and rigorous analysis of the data that would have potentially valuable interpretations. As soon as this data is available, we initially run macro-level analyses that could shed light on the influence of bots on making a conversation trendy, or more generally, on the formation of a collective identity. This includes, but is not limited to, evaluating the share of bots of the network (both content and friendship networks) involved in each particular conversation over time. At the next stage of the data analysis, we plan to make use of standard network analysis methods, such as centrality measures, to evaluate the relative importance of bots in the network corresponding to each content. Although various candidate analysis techniques, such as methods for evaluating cascade on networks, information diffusion in multilayer networks (friendship, and content), and constructing a gravity field of contents have been discussed in our group, we would prefer to avoid claiming any of these to be useful and keep our options for the technical aspects of the next stage considerably open. In the light of the results from the initial macro-level analyses, we could get a more concise idea of what particular methods would produce more informative results and could be generalizable in other media, societies, or contexts.